This post is about Dynamic Tree Cut, the method used, together with hierarchical clustering, to identify modules (clusters) in WGCNA. To put this post in context, in WGCNA, through several steps, one constructs a variable-variable similarity matrix which is then used for clustering. (The clustering similarity is usually the Topological Overlap Matrix, TOM, but it is not a requirement). The similarity is then turned into a dissimilarity where higher numbers mean more dissimilar (distant) variables. The dissimilarity is used as input to a clustering method, which in WGCNA is the above-mentioned hierarchical clustering and Dynamic Tree Cut. The hierarchical clustering produces a structure called the dendrogram or clustering tree, and Dynamic Tree Cut identifies clusters as branches in the clustering tree. The clustering tree and the module labels are visualized together, as in the plot below.

I get asked a lot why there is often an apparent disagreement between a clustering tree and module colors. In the plot above, some colors are split into a few blocks, colors sometimes overlap, it’s hard to figure out where a module begins and where it ends. People would rather see colors neatly arranged into blocks that correspond to branches, something like this:
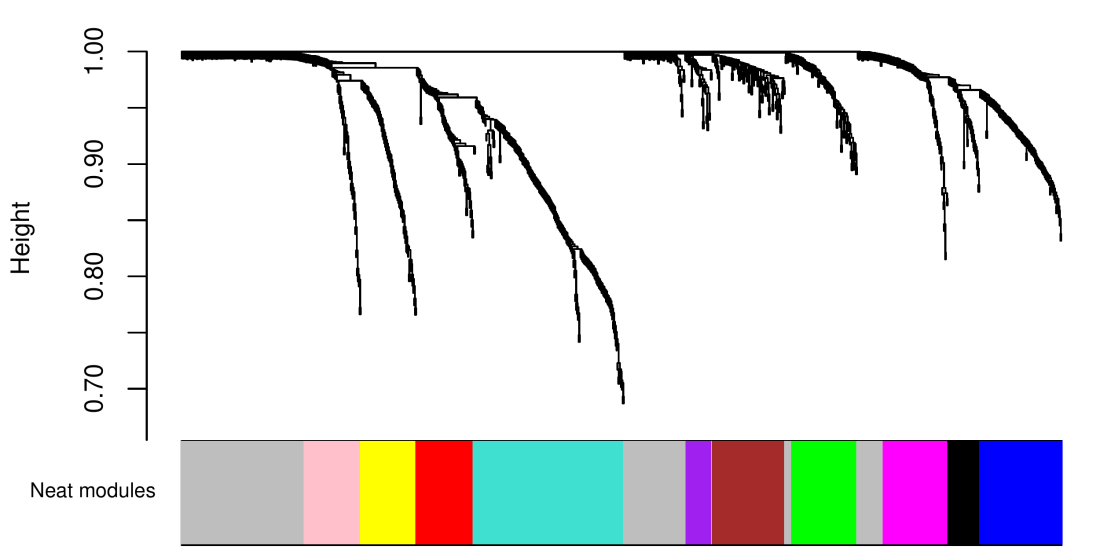
Maybe there’s a bug somewhere deep inside Dynamic Tree Cut?
Although I wouldn’t bet my life on there being no bugs in Dynamic Tree Cut, this is most certainly a feature, or perhaps more accurately, it simply reflects a limitation of the dendrogram as a means of visualizing similarities of a large number of objects rather than something specific to Dynamic Tree Cut. Let me explain what I mean on a simple example. Look at the points in this figure:
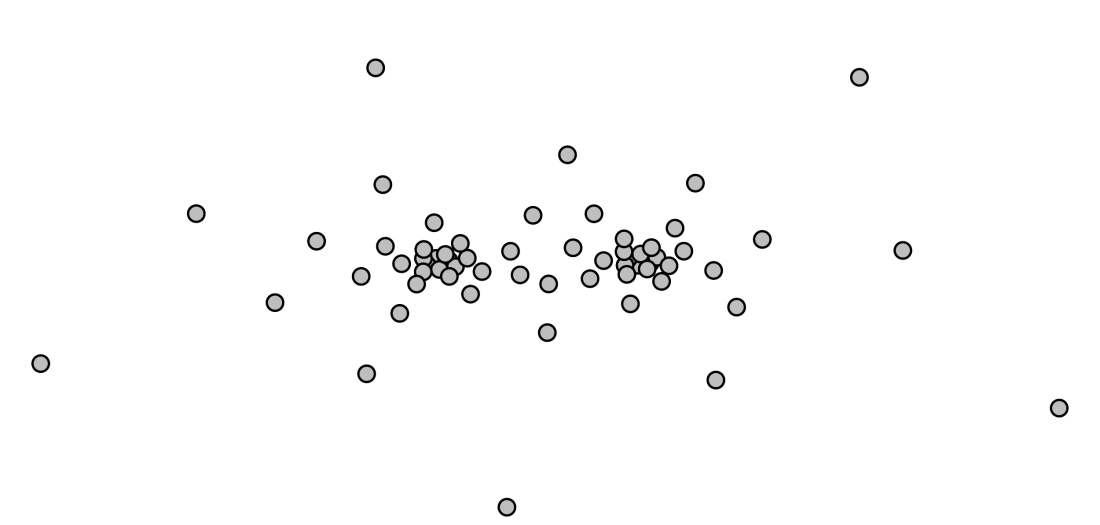
There are two clusters, relatively close together, with some outlying points scattered around the two clusters. If I was told to split the data into two clusters by hand, I would draw a line down the middle and call one side the blue cluster and the other the red one:

Of course, we want the computer to do the hard work for us, and we’ll let the duo of hierachical clustering and Dynamic Tree Cut do its work here. Here’s what clusters this method comes up with:
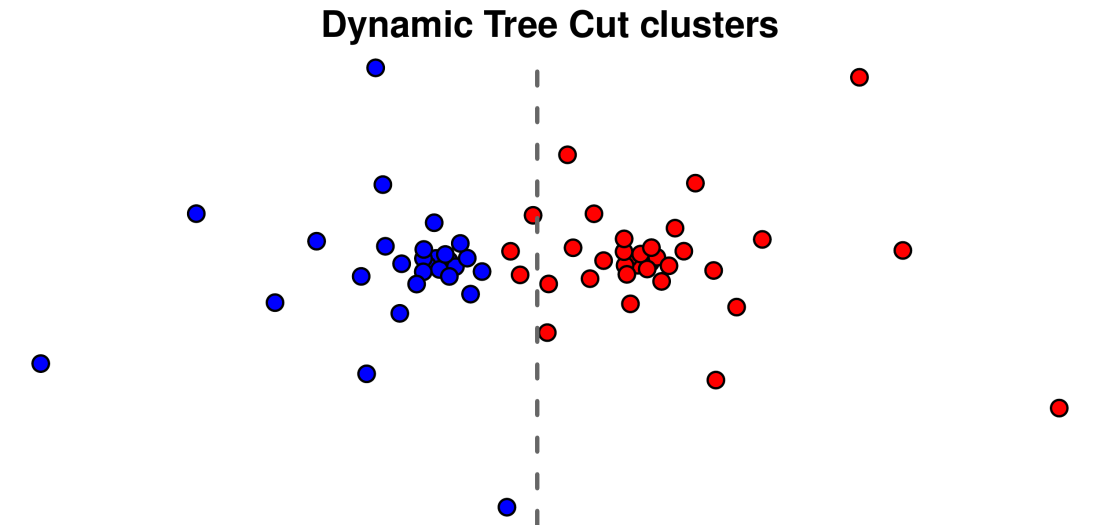
The clustering did a pretty good job, splitting the points nearly exactly along the same line. Now look at the the dendrogram and the cluster colors below it:
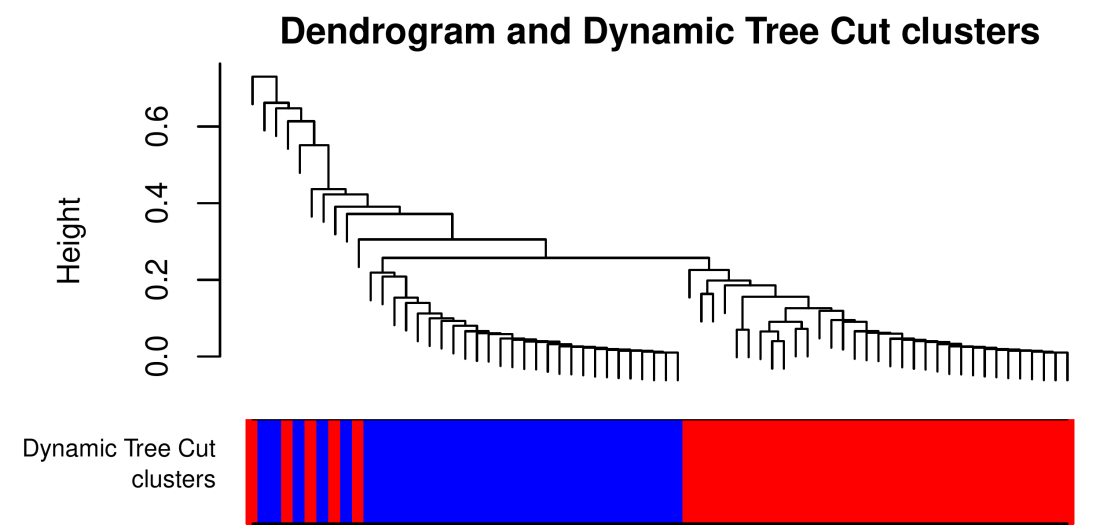
The branches carry solid colors, as one would expect, but the points above (or to the left) of the branch merge are a mixture of blue and red. Why is that? Let’s zoom in on that part of the dendrogram and label the points with numbers 1 to 10:
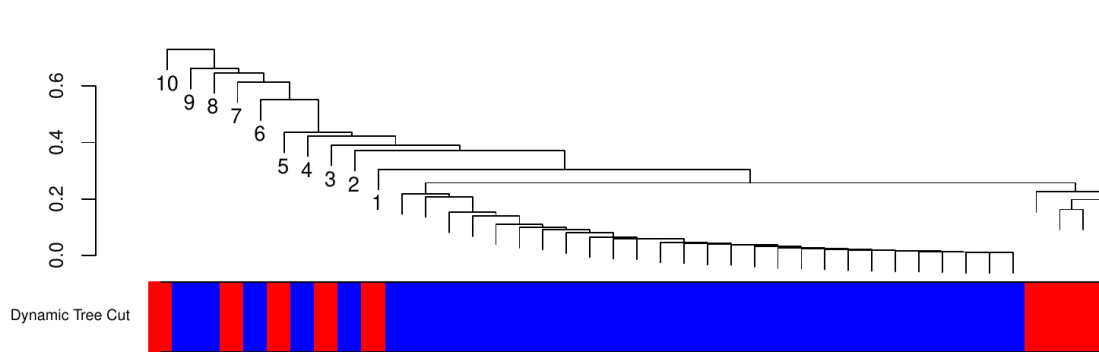
Now I label the the same points in the original 2-dimensional plane:
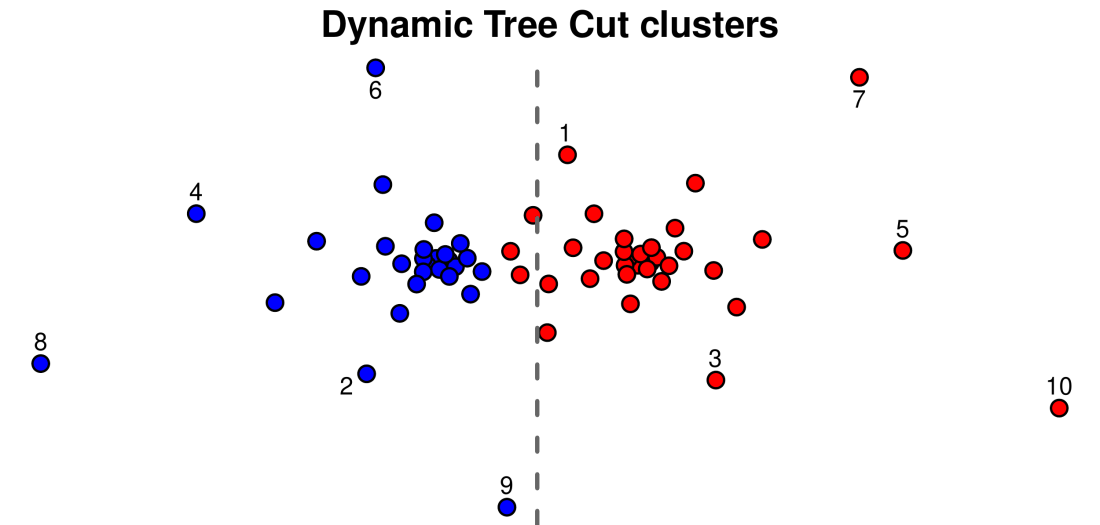
It is now hopefully clear why the points numbered 1-10 have the colors they have: each point is assigned to the cluster that is closest to it. This makes perfect sense in the two-dimensional plane; it is only on the dendrogram that the points 1-10 are ordered seemingly randomly and the colors end up intermixed. This is really a limitation of the dendrogram, not of the Dynamic Tree Cut. And what would happen had we used a method that makes the cluster colors concordant with the dendrogram? Here’s how such a cluster assignment might look:

The blue cluster now extends past the merge with the red cluster, all the way up to the top. Looks nice when viewed with a dendrogram, but what about the two-dimensional view of the points? Here it is:
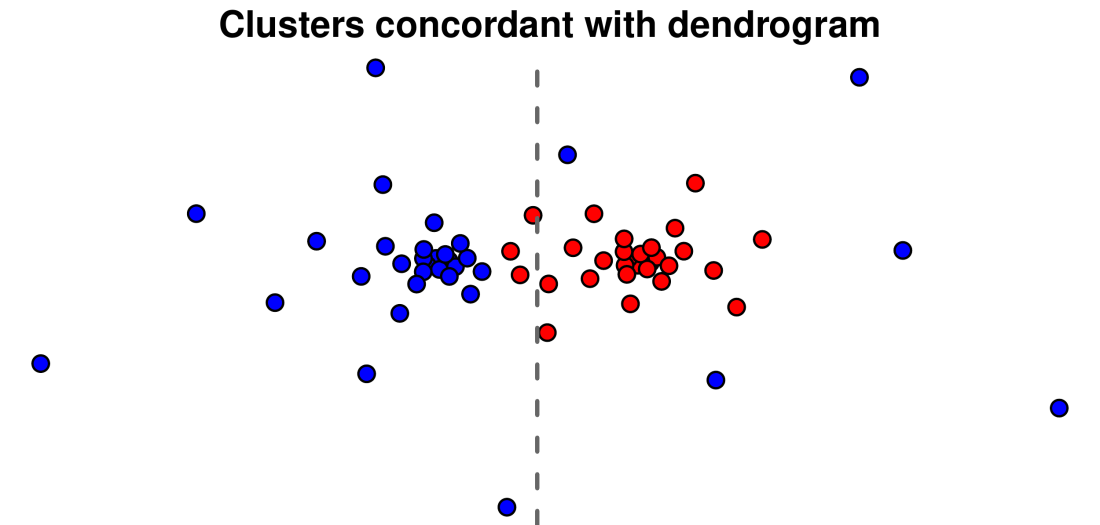
The outlying points around the red cluster are now colored blue, which makes very little sense. So there you have it: once two clusters merge on the dendrogram, any points that are merged above that may belong to either of the two clusters, and won’t form contiguous blocks of colors like the branches do. This also means that such outlying points cannot be assigned to clusters just based on the dendrogram; one needs the dissimilarity matrix to assign each point to its nearest cluster. This is what Dynamic Tree Cut does (at least in its default, “hybrid” form) and it’s why the colors under the dendrogram are correct, even if they look perhaps a bit messy. After all, data analysis is not a beauty contest!
